什么是知识库
什么是知识库
大模型的训练数据,是公开而普世的知识数据,当你问它你的企业、或者某个领域非常专业的问题时,它无法给出准确的回答。知识库相当于Agent的“外部资料库”,当被问到不懂的问题时,Agent先去知识库里查询一番,根据查询出的内容,自己总结以后再回答给你。
我们可以类比“人工客服”的场景,用户来询问一个产品问题,接待的客服人员,如果他不知道如何回答,会先在企业的知识库里查询一番,有了一些信息以后,自己整理再回答用户。Agent也是同样的工作方式,这个过程被称为RAG(Retrieval-Augmented Generation,检索增强生成)。
使用场景
- 智能客服,上传你公司产品的知识文档或者QA问题对,Agent可以成为你公司的AI客服,回答常见的客户问题,你给的资料越丰富,它能回答的问题就越多
- 领域专家,上传某个领域专业的材料文档,Agent可以成为这个领域的专家,你可以参考我们的模板应用杭州老蒜苔汽车维修,它的知识库里有100多个汽车专业的文档,让Agent马上成为一个汽车维修领域的专家
大致工作原理
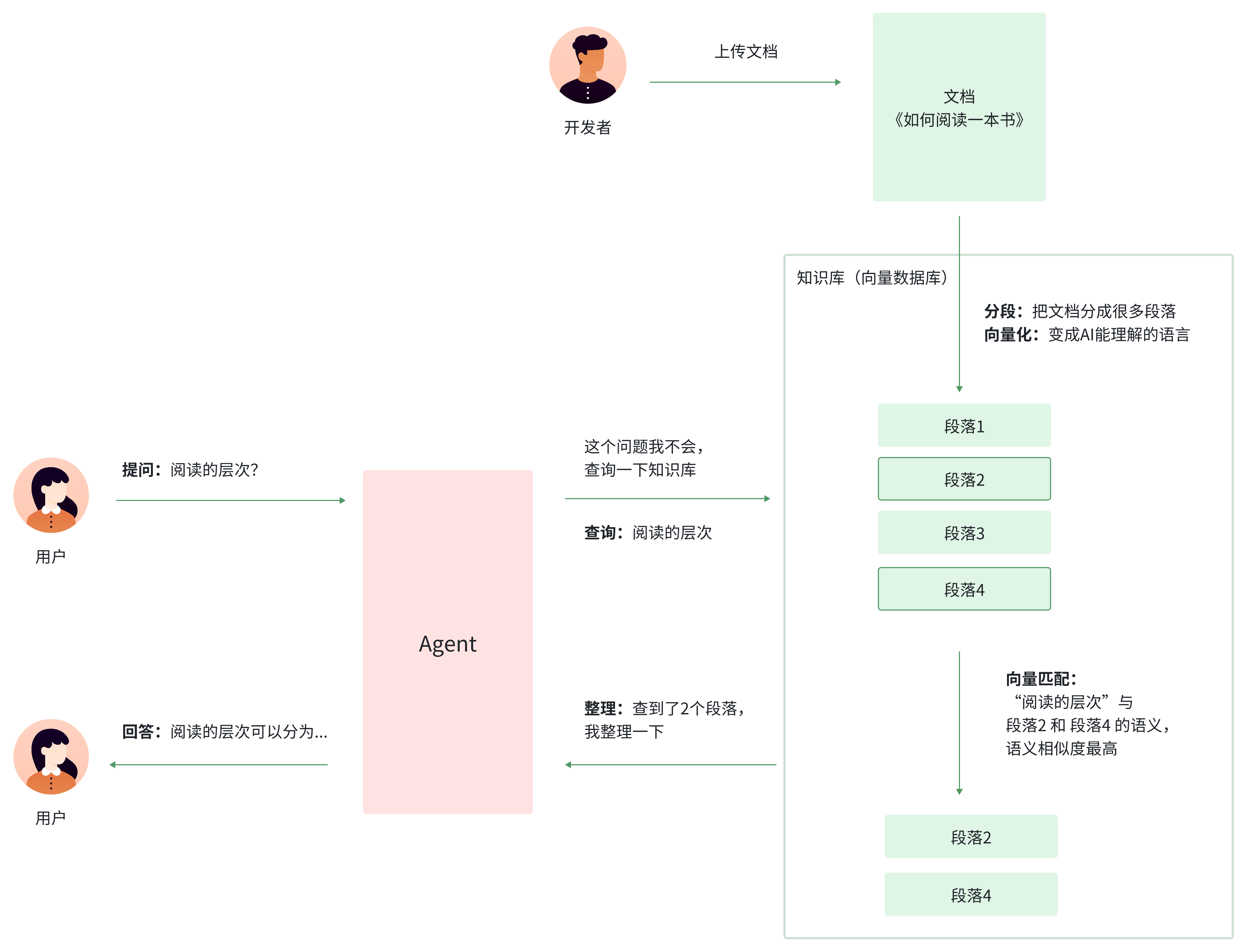 在过程中,有几个关键的概念:
在过程中,有几个关键的概念:
分段
文档被存入知识库时,会被分成很多段落,每个段落在200-1000个字之内,这样做是为了方便检索。可以参考下图,左边是原始文件,右边是实际分段后的效果 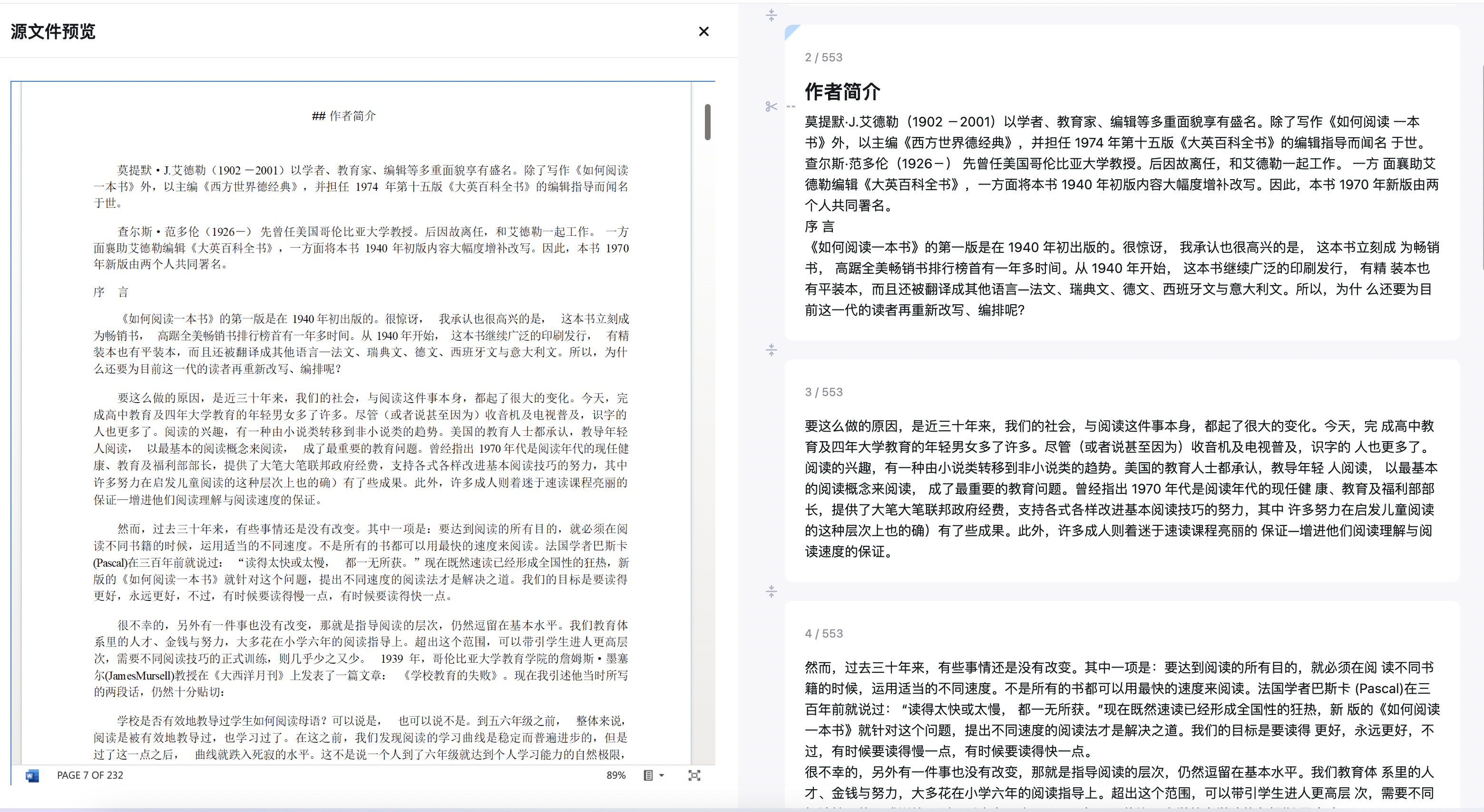
向量化
把文字内容,变成类似[0,10,3,32,..]这样的数组,这是大模型能够理解的数组形式,这是背后的工作方式,可以先暂时不用过多的理解。
向量匹配
拿“阅读的层次” 和所有段落进行向量匹配,判断这句话和哪一段的语义最接近,每一个匹配都会有一个“相关度”,相关度越高,代表语义越接近。如下图所示,左边的三个段落,和查询的语句,相关度是最高的。但是如果直接把这三个段落直接返回,是混乱无法阅读的,这就需要Agent的重新整理。 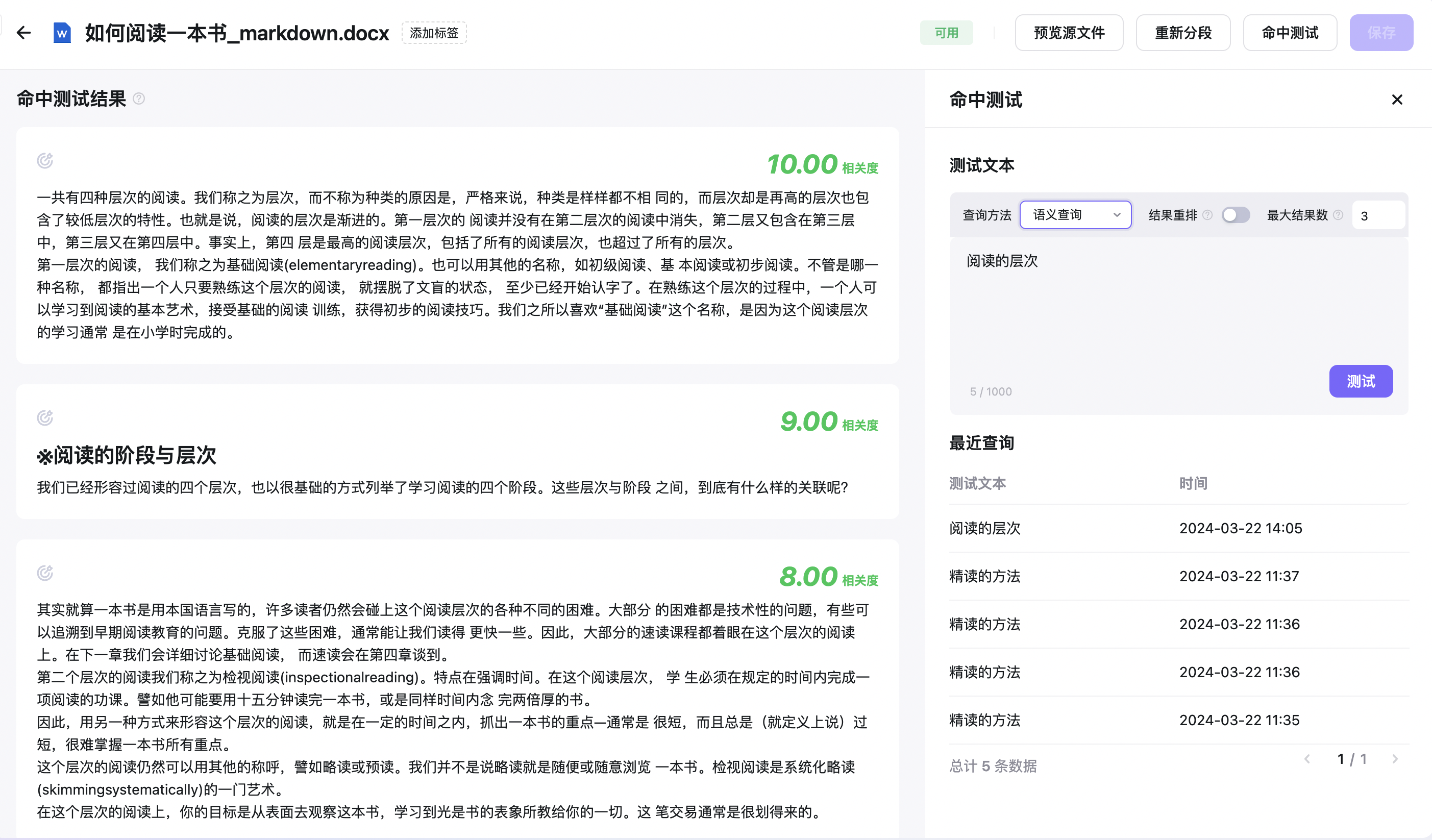
Agent重新整理
知识库查询到了三个段落后,他会根据自己的理解重新整理,让用户更好的阅读 